標準偏差とは|簡単解説

標準偏差のカンタン解説
標準偏差はデータが平均を中心にどの程度バラついているかを知るための基本統計量です。分散の平方根が標準偏差にあたり、分散は偏差の2乗を平均することで求められます。
標準偏差は基本統計量のひとつ
標準偏差はデータのバラつきの度合いを表す基本統計量のひとつです。
基本統計量はデータ全体から得られる情報を1つの値で表現することを目的とするもので、基本統計量を求めることを「データを要約する」といいます。
基本統計量には平均値、中央値、最頻値などのデータ全体の中心と見なせる値を求めるものと、標準偏差や分散などのデータ全体のバラつきの度合いを表すものがあります。
平均値とは|簡単解説
平均値のカンタン語句解説 平均値は基本統計量のひとつであり、中央値、最頻値とともにデータ全体の中央傾向を代表する統計量です。平均値はデータの総和をデータの個数で…

中央値とは|簡単解説
中央値のカンタン語句解説 中央値とは、データを大きい順(もしくは小さい順)に並べたときに中央に位置する値です。メディアンもしくはメジアン(英 median)とも呼ばれ…

最頻値とは|簡単解説
最頻値のカンタン語句解説 最頻値は、データ全体のなかで最も頻繁に現れる値のことです。平均値、中央値と合わせてデータ全体の中心を表す指標のひとつです。 最頻値の概…

標準偏差の求め方
標準偏差と分散は、どちらも平均を基準としてデータのバラつきの度合いを算出するもので、標準偏差は分散の平方根で求められます。
標準偏差 = √分散 標準偏差2 = 分散
標準偏差を求めるために分散を計算します。分散は個々のデータと平均値の差(偏差)の2乗を合計し、データの個数で割ったものです。
分散 = 偏差2の平均 = 偏差2の合計/データの個数 (偏差 = 平均値 ー 個々のデータ)
偏差とは平均値と各データの差のことです。偏差は合計すると0になり、偏差の平均を求めることができません。そのため偏差を2乗することで平均を求められるようにしたものが分散です。
分散は偏差を2乗して平均を求めているため、単位をもとに戻すために平方根をとったものが標準偏差ということができます。
実際のデータ(内閣府「県民経済計算(令和元年度)」)を使って分散と標準偏差を求めてみると以下のようになります。
【地域別1人当たり県民所得(令和元年度)】
| 地域 | 所得 | 偏差 | 偏差2 | |
|---|---|---|---|---|
| 北海道・東北 | 286 | ー26 | 676 | |
| 関東 | 392 | 81 | 6,561 | |
| 中部 | 339 | 28 | 784 | |
| 近畿 | 304 | ー7 | 49 | |
| 中国 | 300 | ー11 | 121 | |
| 四国 | 287 | ー24 | 576 | |
| 九州 | 269 | ー42 | 1,764 | |
| 合計 | 2,117 | 0 | 10,531 | |
| 所得の平均 311 | 分散 = 偏差2の平均 = 1,504 | |||
標準偏差 = √分散 =√1,516 =38.8
上記をグラフにすると以下のように表すことができます。
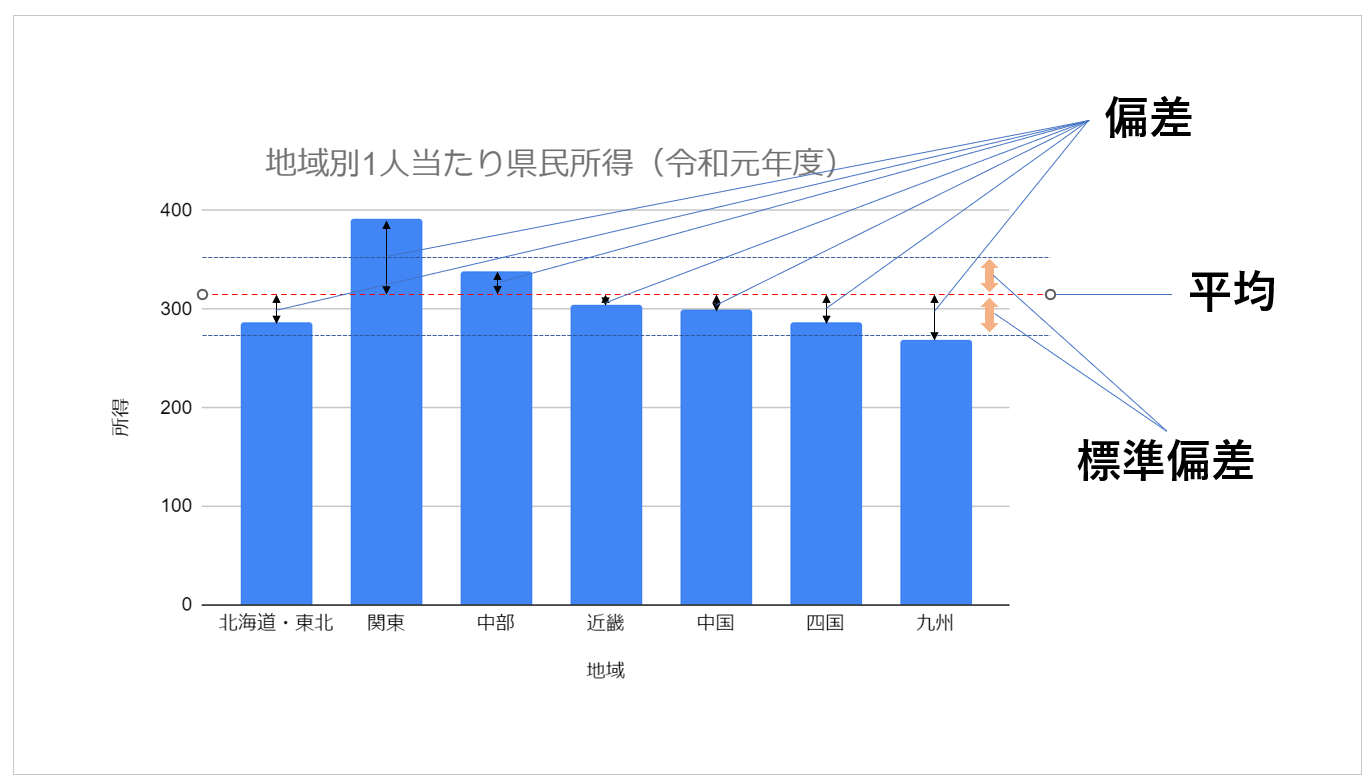
7個の地域別県民所得のうち、最も高い関東と最も低い九州以外の5つの地域は平均311万円の標準偏差 ±38.9万円の範囲に入っており、標準偏差を見ることで、データ全体のバラつきの度合いがどれくらいの範囲かを知ることができます。
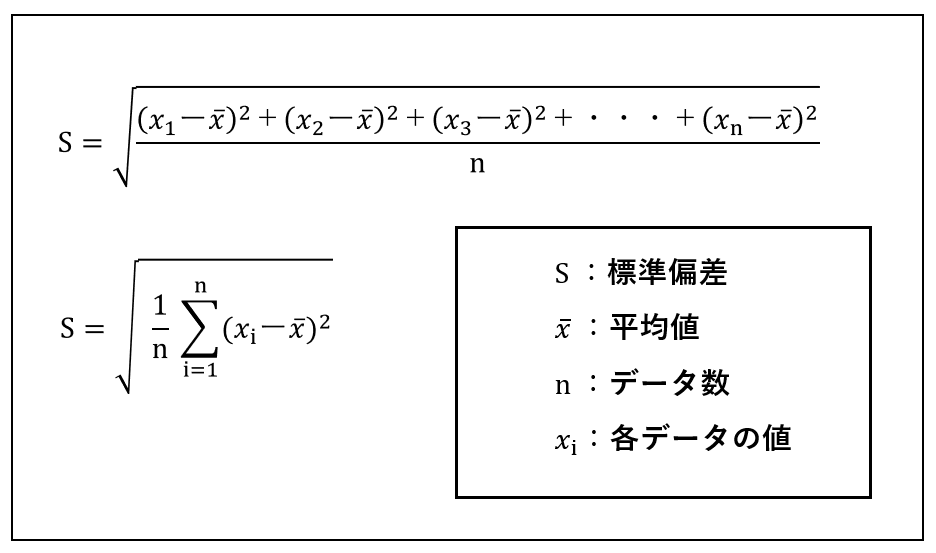
標準偏差の公式
標準偏差の公式は以下の数式で表されます。
標準偏差と正規分布
収集したデータのバラつき具合を標準偏差で見る場合に、正規分布と合わせて考えることでデータの応用範囲が広がります。
正規分布とは、観測されるデータの発生頻度が平均(期待値)を頂点とし頂点から離れるほど少なくなっていくことを表したモデルであり、自然現象や社会現象として観測される事象の多くが、その起こる確率は正規分布に従うものとして知られています。
具体的には、身長や体重のほか、規模の大きいテストの点数、不良品の発生率、通話時間などが正規分布に近い値を取る例として挙げられます。
正規分布は以下のようなグラフで表されます。平均を0、標準偏差を1とした場合の標準正規分布を描いています。標準正規分布は元になるデータから平均を引いて、標準偏差で割り戻すことで得られます。
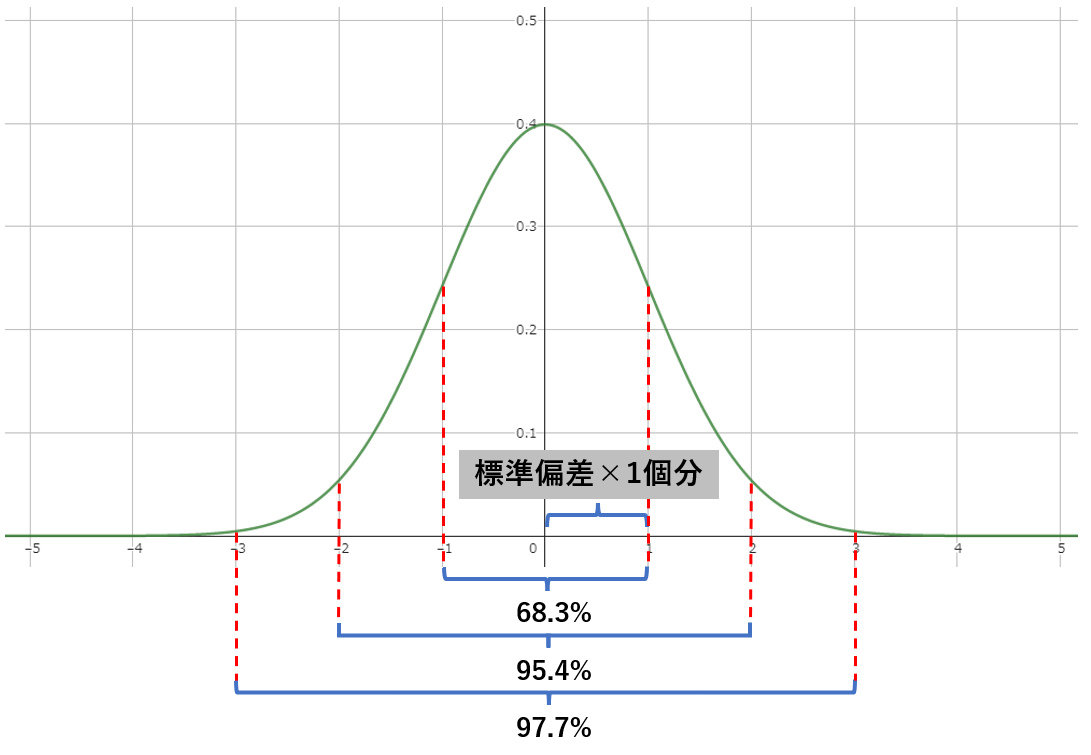
また、正規分布曲線では曲線に囲まれた面積が起こりうる確率に相当し、平均から±標準偏差1つ分までの範囲に起こる確率が68.3%、平均から±標準偏差2つ分までの範囲では95.4%に定まることがわかっています。
得られたデータの標準偏差を算出したときに、データの集合が正規分布に従うと考えられる場合、平均±標準偏差1つ分の範囲に全体の7割弱が存在していると考えることができます。
偏差値の計算に使う標準偏差
標準偏差を求めることで分布の異なるデータの集合間の比較が可能になります。これを応用したものが学生の模擬試験などで使われている偏差値です。偏差値を使うことで母集団のなかでどの位置にいるかがわかります。
偏差値 = 得点 ー x 平均点)/ s(標準偏差) ✕ 10 + 50
得点から平均点を引いた値を標準偏差で割ることで標準偏差が1である分布に変換されます。点数の粒度に揃えるために10倍し、平均を50点に移動させたものが偏差値ということになります。
標準偏差のビジネスへの応用
標準偏差はビジネスのさまざまな場面で使われています。
工業製品の品質管理
工業製品の製造では、寸法や重量がぴったり設計通りということは不可能であり、許容される極わずかな範囲でのバラつきが存在します。
許容されるバラつきの範囲は管理限界と呼ばれ、製造品のバラつきを管理限界に収めるために品質管理を行い工程の能力を保つことが求められます。
良品率は正規分布に従い ±3σ(σ=標準偏差1つ分)では97.3%、±6σでは99.9997%の良品率を実現できることから、基準となる管理限界を定めて抜き取り検査の結果から良品率を推定し工程能力を管理します。
需要予測による在庫管理
需要のバラつきが大きい商品は在庫の標準偏差も大きくなるため、バラつきの大きい商品は多めの安全在庫が必要で、バラつきの小さい商品は少なくて済むということになります。
安全在庫は以下の式で計算されます。
安全在庫 = 使用量の標準偏差 ✕ 安全係数 ✕ √(発注リードタイム + 発注間隔)
※安全係数は欠品リスクの許容範囲、一般的には1.65(欠品許容率5.0%)が用いられる
周期的な需要変動がある商品では、過去の実績をもとに需要量を予測することができます。
この場合は、使用量の標準偏差ではなく、予測と実際の誤差の標準偏差を取ることで安全在庫をより少なくすることが可能になります。
安全在庫 = 予測誤差の標準偏差 ✕安全係数 ✕ √(発注間隔 + 調達期間)
多変量解析で用いられる標準偏差
マーケティングリサーチの定量分析でも多くの場面で標準偏差が用いられます。主成分分析、因子分析、判別分析を行う際の変数の正規化(標準化)、相関係数の公式、クラスター分析の距離の計算など、分析を行うなかでよく使われる統計量といえます。
まずは使って慣れてみること
記事で紹介したように、標準偏差は広く用いられている統計量であり、さまざまな統計分析手法を理解するうえでも前提となる知識です。計算の工程が複雑であり使い方のイメージも湧きにくい部分がありますが、具体例に当てはめて計算してみるとわかりやすくなります。