分散とは|簡単解説

分散のカンタン語句解説
分散とはデータの散らばり具合を示す基本統計量のひとつです。データの偏差の二乗和をデータの個数で割ったものが分散で、標準偏差や共分散、相関係数の計算にも分散が使われます。
分散とは
基本統計量は平均や中央値などのデータ全体を一つの値に要約するための代表値と、データ全体のバラつき具合を表す散布度に分けられます。分散は散布度を表す基本統計量のひとつであり、偏差の二乗和の平均で求められます。
| 基本統計量 | 代表値 | 平均 | データの総和 / データの個数 |
| 中央値 | データ順位の中央の値 | ||
| 最頻値 | 度数・確率が最大の値 | ||
| 最大値 | データのなかで最も大きい値 | ||
| 最小値 | データのなかで最も小さな値 | ||
| 散布度 | 範囲 | 最大値と最小値の差 | |
| 分散 | 偏差(平均値と各データの差)²の合計 / データの個数 | ||
| 標準偏差 | 分散の平方根 | ||
| 歪度 | データのバラつきの偏り | ||
| 尖度 | データのバラつきの集中度 |
分散は以下の公式で求められます。
S2:分散 、n:データ個数、データの値:xi、 平均値:xS2 = 1ni=1n(xiーx)2 =偏差2の合計データの個数
分散から標準偏差を求める
分散が偏差二乗和の平均を取るのは、偏差の合計は0になり平均を求めることができないためです。
2乗して求めた分散の値の平方根を取り、元の単位に戻したものが標準偏差です。標準偏差は平均を中心として、どの程度の範囲にデータが収束しているかを見る際に役に立ちます。
標準偏差とは|簡単解説
標準偏差のカンタン解説 標準偏差はデータが平均を中心にどの程度バラついているかを知るための基本統計量です。分散の平方根が標準偏差にあたり、分散は偏差の2乗を平均…

共分散
分散が1組のデータの散らばり具合を表すのに対し、共分散は2組のデータ(2変量)を対象としてデータの散らばり具合(変動)が似ているかどうかを表します。
共分散は2変量の「偏差の積の平均値」で求めることができます。
2変量をx,y、x,yの共分散をSxyとすると、Sxyは以下の公式で表すことができます。
x,yの共分散:Sxy 、n:データ個数、データの値:xi,yi、平均値:x,ySxy =1ni=1n(xiーx)(yiーy)
2変量の共分散の値によって以下の関係が成り立ちます。
共分散 > 0 → 2変量は一方が増加するともう一方も増加する。
共分散 = 0 → 2変量は関連性がない。
共分散 < 0 → 2変量は一方が増加するともう一方は減少する。
具体的な例として、地域別1人当たり県民所得と地域別県内就業者数のデータをもとに共分散を求めてみます。
| 1人当たり所得(万円) | 所得の偏差ー① | 就業者数(万人) | ②就業者数の偏差ー② | ①✕②偏差の積 | |
|---|---|---|---|---|---|
| 北海道・東北 | 286 | ー25 | 805 | ー143.6 | 3,590.0 |
| 関東 | 392 | 81 | 2,524 | 1,575.4 | 127,607.4 |
| 中部 | 339 | 28 | 977 | 28.4 | 795.2 |
| 近畿 | 304 | ー7 | 1,050 | 101.4 | ー709.8 |
| 中国 | 300 | ー11 | 374 | ー575.6 | 6,331.6 |
| 四国 | 287 | ー24 | 190 | ー758.6 | 18,206.4 |
| 九州 | 269 | ー42 | 720 | ー228.6 | 9,601.2 |
| 合計 | 2,117 | 6,640 | 165,422.0 | ||
| 平均 | 311 | 948.6 | 23,631.7 |
地域別1人当たり県民所得と地域別就業者数の共分散は、23,631.7と正の値であり、県民所得が高い県は就業者数も多いということがいえます。
共分散から相関係数を求める
共分散で求められる数値は2変量の単位に依存するため、共分散だけでは2変量に線形的な関係があるかどうかしか判断することができません。
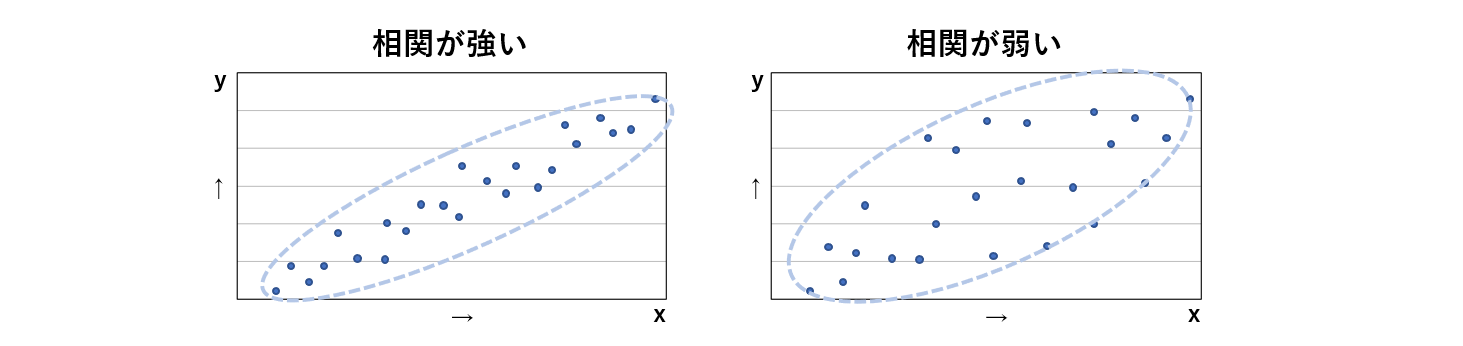
一方が増加するともう一方も増加する(または、減少する)という2変量の線形的な関係を相関といいますが、共分散を正規化することで相関の強さを表せるようにしたものが相関係数です。
2変量をx,y、x,yの相関係数を r とすると、rは以下の公式を表すことができます。
x,yの共分散:Sxy、xの標準偏差:Sx、yの標準偏差:Syr (相関係数)=SxySx・Sy =x,yの共分散xの標準偏差✕yの標準偏差
相関係数はー1≦ r ≦ 1 の範囲を取り、1に近いほど正の相関が強く、ー1に近いほど負の相関が強いことを表します。0に付近ではほとんど相関がないということになります。
地域別1人当たり県民所得と地域別就業者数の相関係数を求めると0.74となり、強い正の相関があることがわかります。
| 1人当たり所得(万円) | 所得の偏差ー① | 就業者数(万人) | ②就業者数の偏差ー② | ①✕②偏差の積 | |
|---|---|---|---|---|---|
| 北海道・東北 | 286 | ー25 | 805 | ー143.6 | 3,590.0 |
| 関東 | 392 | 81 | 2,524 | 1,575.4 | 127,607.4 |
| 中部 | 339 | 28 | 977 | 28.4 | 795.2 |
| 近畿 | 304 | ー7 | 1,050 | 101.4 | ー709.8 |
| 中国 | 300 | ー11 | 374 | ー575.6 | 6,331.6 |
| 四国 | 287 | ー24 | 190 | ー758.6 | 18,206.4 |
| 九州 | 269 | ー42 | 720 | ー228.6 | 9,601.2 |
| 合計 | 2,117 | 6,640 | 165,422.0 | ||
| 標準偏差 | 41.8 | - | 760.6 | - | - |
| 平均 | 311 | - | 948.6 | - | 23,631.7 |
相関分析とは|簡単解説
相関分析のカンタン語句解説 相関分析は2つの変数の関係性を調べるために使われる統計手法です。一方の変数の変化にともない、もう一方の変数もある程度の規則性を持って…

相関係数を応用したポートフォリオ分析
相関係数を使ったアンケート調査の分析方法にポートフォリオ分析があります。2つのカテゴリーデータの相関係数を算出し、相関係数からカテゴリーのポジショニングを行う方法です。
典型的なものとして顧客満足度調査(CS調査)のポートフォリオ分析が挙げられます。
以下は、スーパーマーケットの顧客満足度調査におけるポートフォリオ分析の事例です。
スーパーマーケットの顧客満足度を実施し、総合満足度を高めることに寄与している個別項目を相関係数を用いて可視化し、改善施策の優先順位付けを行うことを目的とします。
個別の評価項目の満足度率と総合満足度の相関係数を求めます。
| 評価項目 | 満足度率(5段階評価の上位2つ) | 相関係数 |
|---|---|---|
| 惣菜が美味しい | 55.0 | 0.624 |
| 品揃えが豊富 | 50.0 | 0.594 |
| 価格が手頃 | 45.0 | 0.721 |
| 生鮮食品が新鮮 | 40.0 | 0.608 |
| レジの処理が速い | 40.0 | 0.556 |
| 店内が明るい | 40.0 | 0.286 |
| 陳列が見やすい | 25.0 | 0.442 |
| 品切れが少ない | 15.0 | 0.685 |
| 従業員の対応が良い | 10.0 | 0.238 |
| 総合評価 | 45.0 | 1.000 |
| 平均 | 35.6 | 0.528 |
クロス・マーケティング「ポートフォリオ分析」のデータをもとに以下のような散布図を作成し、個別項目の満足度率と総合満足度との相関係数をプロットします。
横軸に取った相関係数は総合満足度に対する影響の大きさを表し、縦軸の満足度率は個別評価項目の満足度の高さを表しています。
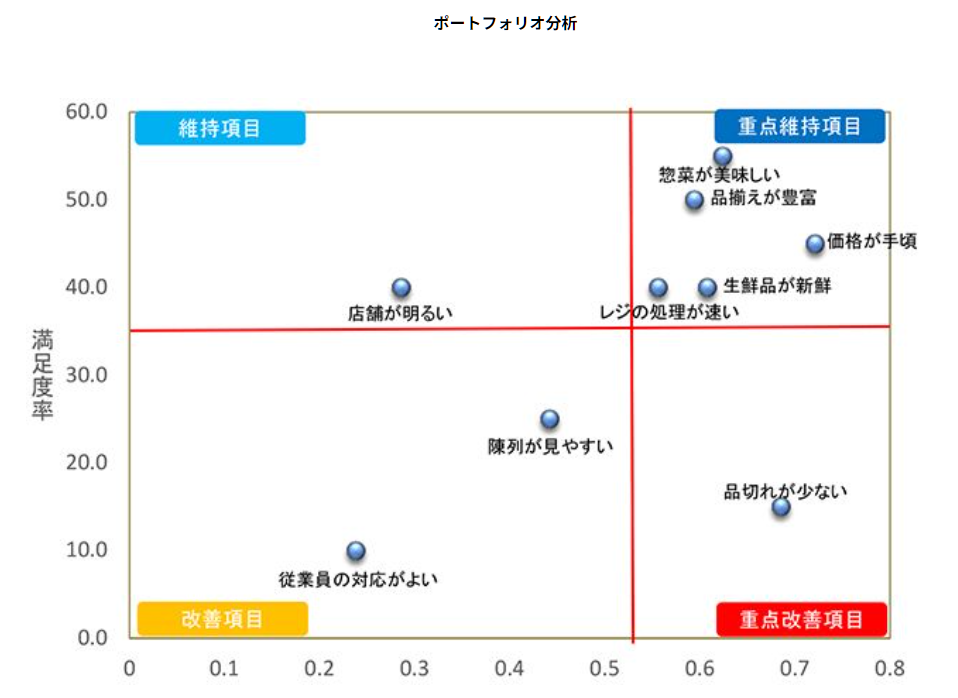
①重点改善項目(右下)
「品切れがない」は、総合満足度に大きく影響する項目であるにも関わらず評価を得られていません。個別項目のなかでは最優先で改善に取り組むべき項目に位置づけられます。
②重点維持項目(右上)
総合満足度と相関が強い個別評価項目(「惣菜が美味しい」「品揃えが豊富」「価格が手頃」「生鮮食品が新鮮」「レジの処理が速い」)は総合満足度を高めることにつながる個別項目です。個別項目としても高評価が得られているため、現状の水準を維持することに注力すべき項目です。
④改善項目(左下)
「陳列が見やすい」「従業員の対応が良い」は総合満足度への影響度、個別項目としての評価ともに低く、満足度の低いという点では改善が必要な項目ですが、総合満足度に対する影響度が低いため改善施策の優先度は低くなります。
③維持項目(左上)
「店内が明るい」は個別項目として評価は得られており、総合満足度への影響度も相対的に低いと考えられることから、改善への取り組みに対する優先順位は低くなります。
まとめ
標準偏差や相関係数など、よく用いられる統計量を理解するための基本となるのが分散です。また、統計的検定や確率を扱う際にも用いられる重要な統計量に位置づけられます。
ポートフォリオ分析で見たように、データのバラつきからさまざまな情報を取り出すことができるため、分散を理解しておくことは統計データを扱う際に役立ちます。

