生成AIとシンセティックユーザーの時代にこそ、リアルなユーザー調査が欠かせない理由

生成AIの活用はマーケティングやリサーチの現場にも急速に広がっています。そのなかで注目されているのが、LLM(大規模言語モデル)を顧客や回答者に見立てる「シンセティックユーザー(合成ユーザー)」です。
AIペルソナやシリコンサンプルといった手法は、仮説づくりや調査設計を高速化する一方で、バイアスの増幅や実態との乖離、誤った確証といった負の側面も抱えています。
本記事では、国内外のシンセティックユーザーの動向とリスクを整理しながら、AIリサーチの正しい立ち位置と、実ユーザー調査が果たすべき役割を考えます。
1.シンセティックユーザー(合成ユーザー)とは
シンセティックユーザー(Synthetic User)とは、LLM(大規模言語モデル)を顧客や回答者に見立て、アンケートやインタビュー、行動シミュレーションなどを行う手法や、そのAIエージェントの総称のことです。
こちらの記事で、生成AIに回答者の役割を与えてアンケートの調査票をチェックするという使い方を紹介しましたが、この考え方を拡張し、生成AIに顧客や特定のペルソナとして質問に答えさせたり、行動をシミュレートするアプローチが実用化されています。
この「AIによる顧客の代替(AI as user / respondents / customers / audiences)」のアプローチは、目的や用途によって大きく4つの側面に分類できます。
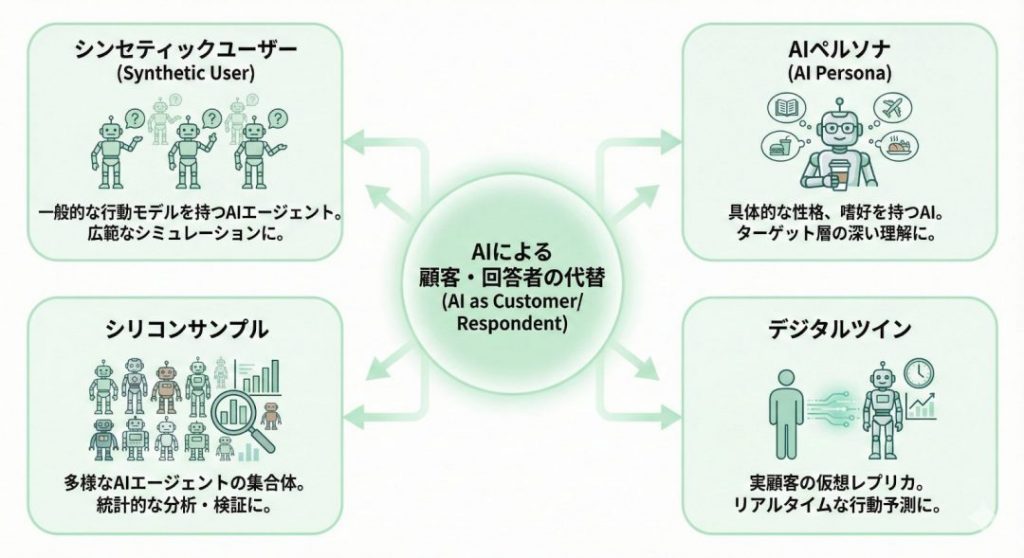
1-1.シンセティックユーザー(Synthetic users / respondents / customers / audiences)
【定義と特徴】
シンセティックユーザーとは、広義には「AIによる顧客代替」全般を指しますが、狭義には「人間の行動や発話モデルを模倣するAIエージェント」そのものを指します。
特定の個人の詳細なプロフィールよりも、「人間のように振る舞うこと(Behavior)」や「タスクを実行すること」に焦点が当てられることが多く、UXリサーチやユーザビリティテスト、あるいは広範な市場シミュレーションにおいて、人間の代役として機能します。
【マーケティング・リサーチでの活用】
最大の特徴は、定性的な反応や行動予測を「シミュレーション可能」にする点です。従来、消費者の反応を見るためには、実際に人を集めてインタビューやアンケートを行う必要がありましたが、シンセティックユーザーを用いることで、企画の初期段階において「仮想の反応」を即座に生成できるようになります。
例えば、新商品のコンセプトやキャッチコピー案に対し、想定ターゲットがどのような印象を持つか、どのような言葉で評価するかといった「定性的なフィードバック」を大量に生成させ、人間が確認すべき論点を事前に絞り込むといった活用が可能です。
これにより、限られたリソースを有効活用し、仮説検証のサイクルを高速化させるための「予備実験」としての役割が期待されています。
1-2.AI personas(AIペルソナ)
【定義と特徴】
AIペルソナは、マーケティング戦略でおなじみの「ペルソナ(架空の顧客像)」を、LLMによって「対話可能な生きた存在」へと進化させたものです。
単なるエージェントとは異なり、年齢・居住地・職業・趣味嗜好・家族構成といった極めて具体的な背景情報(コンテキスト)が付与されています。
最近では、Web解析データ(Google Analyticsなど)やCRMデータから、実在する顧客セグメントの特徴を学習させ、自動生成するサービスも登場しています。
【マーケティング・リサーチでの活用】
AIペルソナは、ターゲット層を深く理解し、共感を構築するために活用されます。 例えば、B2C領域では「成分リテラシーが極めて高いスキンケア層」のような詳細なセグメントを発見し、そのペルソナが好むメッセージをテストすることで、広告の費用対効果(ROAS)を高めるといった活用が進んでいます。
また、B2B領域では、コンタクトが困難な企業のCEOやCFOといった「エグゼクティブ層」のペルソナを生成し、複雑な意思決定プロセス(Buying Center)をシミュレーションすることで、営業戦略の精度を高めるケースも見られます。
従来の「紙に書かれた静的なペルソナ」とは異なり、質問を投げかければ「その人らしい反応」を返すため、プランニングやクリエイティブの検証に革新をもたらしつつあるのです。
1-3.Silicon samples(シリコンサンプル)
主に社会科学や心理学などの学術的な文脈、あるいは統計的な実験において使用される用語です。「個」としての性格よりも、集団としての「サンプルデータ」としての性質に焦点が当てられています。
人間の被験者を集めることが倫理的・コスト的に困難な場合などに、アンケートの回答分布や定量的なスコアをAIで代替・予測するために用いられます。大規模な定量調査の代替手段として研究が進められています。
1-4.Digital Twin(デジタルツイン)
実在する特定の個人の購買履歴、行動ログ、属性データなどを統合し、仮想空間上にその人の完全なレプリカ(双子)を再現する技術です。
シンセティックユーザーが 特定の顧客セグメント(または集団) の「一般的なモデル」であるのに対し、デジタルツインは「実在する個人のリアルタイムな写し鏡」として、 その人特有の未来の行動を予測・再現します。
個別の顧客が次にどのような行動を取るかを予測する際などに威力を発揮しますが、構築には高度なデータ統合基盤が必要となります。
2.シンセティックユーザー活用が注目される3つのメリット
シンセティックユーザーは、「生のユーザー調査を置き換える魔法の弾」というより、リサーチやマーケティングのプロセスを立て直すための補助エンジンとして評価されています。
とくに、①試行回数を増やせること、②現実では拾いきれないターゲットや条件を補完できること、③本番調査のリスクを抑えつつ設計の質を上げられること、の3点がよく語られます。
以下では、それぞれが担う役割と、どこに効いてくるメリットなのかを整理します。なお、ここでの整理はあくまで「実ユーザー調査を補完する使い方」を前提としたものです。
2-1.高速・低コストで「試行回数」を一気に増やせる
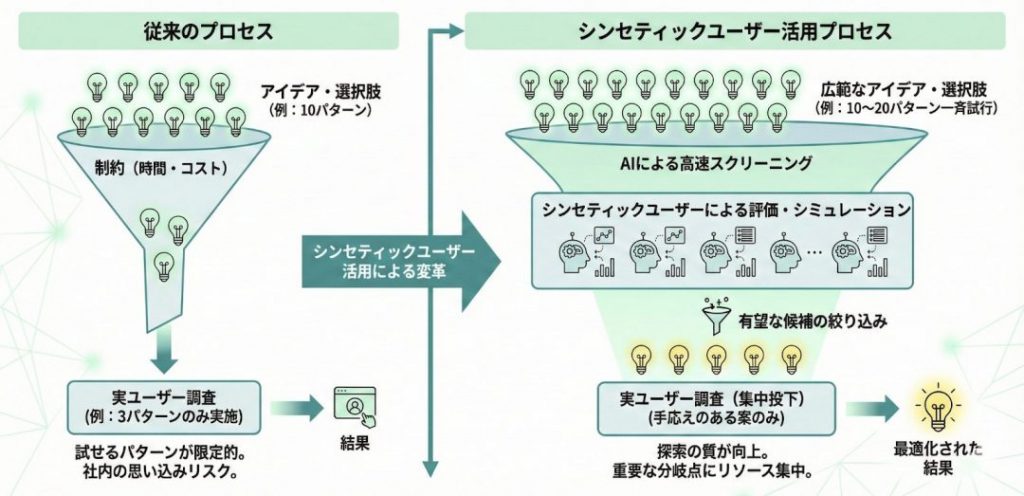
まず分かりやすいのが、時間とコストの制約を緩めて、打席数を増やせるというメリットです。新機能のコンセプト案やキャンペーンコピー、料金プランの組み方など、現場では「本当は10パターン試したいが、調査に載せられるのは3パターンまで」といった制約が常につきまといます。
シンセティックユーザーを使えば、まずAI上で10〜20パターンを一斉にぶつけ、そこから手応えのある候補だけを絞り込んで、実ユーザーに当てにいく、という段取りが可能になります。
ここで重要なのは、「1回の調査を安くする」というよりも、“考えうる選択肢をどこまで広く出して、どこまで絞り込んだ状態で本番に臨めるか”という探索の質を上げる点です。
試行回数が増えると、社内の思い込みだけで候補が絞られてしまうリスクも下がり、企画の初期段階で検討すべきオプションを広く比較検討しやすくなります。そのうえで、本当に重要な分岐点だけは人間の調査リソースを集中的に投下する、というメリハリの効いた使い方ができるようになります。
2-2.現実では集めにくいニッチ層・条件を補完できる
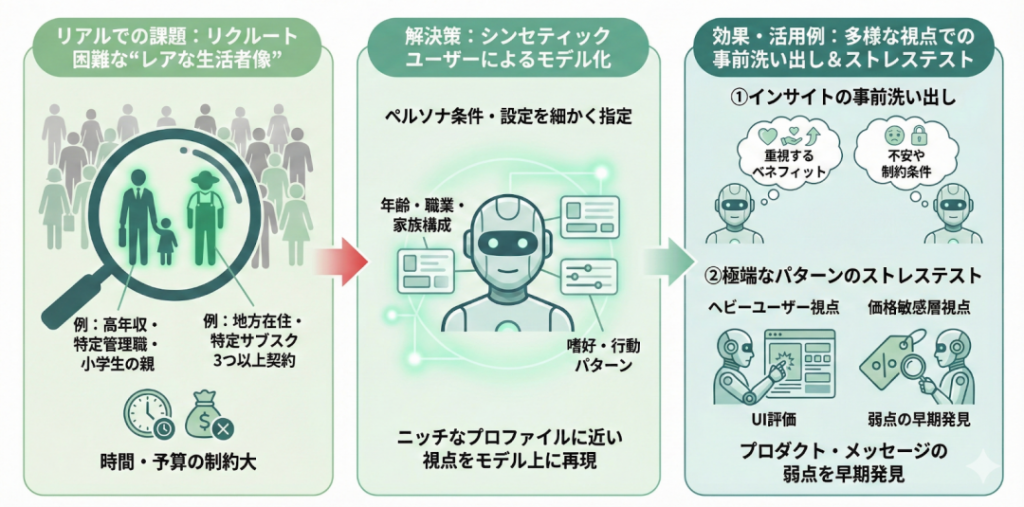
2つ目のメリットは、「そもそも集めるのが難しい声」を、一定の前提のもとで補完できることです。たとえば、「年収が高く、特定業種で管理職をしていて、かつ小学生の子どもがいる親」や、「地方都市在住で、特定ジャンルのサブスクを3つ以上契約している人」など、条件を絞り込めば絞り込むほど、リアルなリクルートコストは跳ね上がります。
こうした“レアな組み合わせの生活者像”について、最初の段階から実在のサンプルを十分な数だけ集めようとすると、時間も予算も足りなくなるのが実情です。
シンセティックユーザーでは、ペルソナ条件や設定を細かく指定することで、そうしたニッチなプロファイルに近い視点をモデル上に再現し、「この属性の人なら、どんなベネフィットを重視しそうか」「どんな不安や制約条件に引っかかりそうか」といった観点を事前に洗い出すことができます。
また、「極端な利用パターン」を想定したストレステストにも向いており、たとえば“ヘビーユーザー視点でUIを評価する”“価格に非常に敏感な層の反応だけを見る”といった切り口で、プロダクトやメッセージの弱点を早期に発見することができます。
2-3.本番調査のリスクを減らし、調査設計の質を高められる
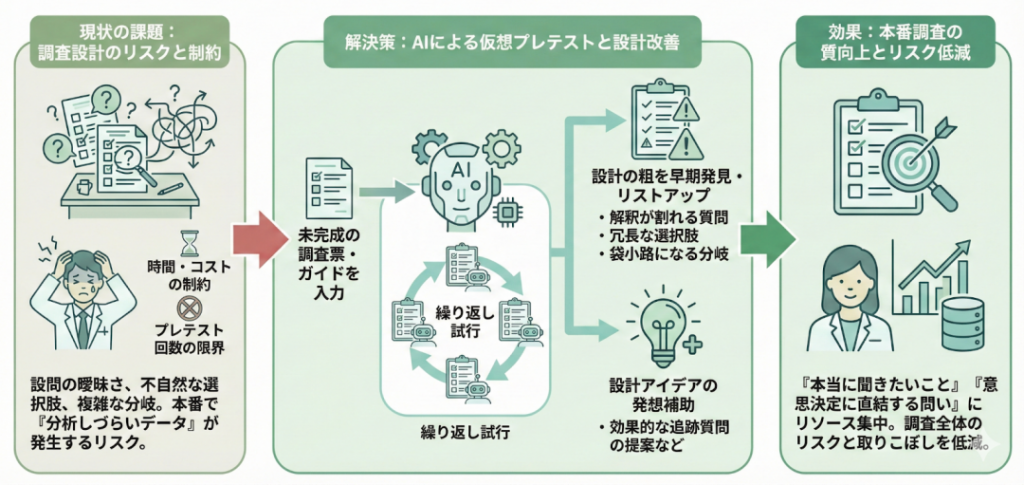
3つ目のメリットは、調査票やインタビューガイドの「設計そのもの」をチューニングするための検査装置として使えることです。アンケートであれば、設問文が曖昧だったり、選択肢の切り方が不自然だったり、分岐ロジックが複雑すぎたりすると、せっかく本番調査を行っても、分析しづらいデータや解釈に困る結果が大量に出てしまいます。
本来であれば、プレテストを複数回まわして設計を見直したいところですが、現実には1回プレテストを打つのが精一杯、ということも多いでしょう。
シンセティックユーザーを使うと、完成前の質問票やインタビューガイドをAI回答者に繰り返しぶつけることで、「この質問は解釈が割れやすい」「この選択肢セットは冗長」「この分岐だと特定のパターンが袋小路になる」といった設計上の粗を、早い段階でリストアップできます。
また、「この設問の後には、こういう追加質問があると解像度が上がりそうだ」といったアイデアの発想補助としても機能します。限られた実ユーザーのサンプルを使う本番調査では、「本当に聞きたいこと」「意思決定に直結する問い」に紙幅と時間を集中させることができ、調査全体のリスクと取りこぼしを減らすことにつながります。
3.シンセティックユーザー関連サービスの全体像と主要プレイヤー
シンセティックユーザーの活用が広まるにつれ、その提供元となるサービスも急速に多様化しています 。現在のこの分野の市場は、大きく2つの主要なプレイヤー群によって形成されています。
一つは、長年にわたり市場調査業界を牽引してきた「大手リサーチ企業・プラットフォーマー」です。これらの企業は既存の膨大なパネルデータとAIを融合させ、信頼性を担保したハイブリッドなソリューションを展開しています 。
もう一つは、生成AIの波に乗って登場した「専業スタートアップ(Synthetic User Generators)」です。特定のニッチなターゲット再現や、APIを通じた柔軟な導入を強みとしています 。 利用企業は、自社の課題が「既存調査の効率化」なのか、「新規顧客の探索」なのかによって、最適なパートナーを選定できる環境が整いつつあります。
3-1.大手マーケティング・リサーチ企業:実データとAIのハイブリッド活用
このカテゴリーにおける最大の特徴は、実在する数千万人規模の消費者パネルや、過去数十年分に及ぶ調査データを「正解データ」として保有している点です 。
NielsenIQやIpsos、Qualtricsといった業界のリーダーたちは、AIを単独で走らせるのではなく、自社が持つ高品質なデータでAIをトレーニング(または検証)することで、出力精度の信頼性を高めています 。
彼らのアプローチの主流は、実際の調査(ヒューマンパネル)と合成回答を組み合わせる「ハイブリッド利用」です 。例えば、初期のアイデア出しやスクリーニングはAIで高速に行い、有望なコンセプトの最終確認は実在の消費者に行うといった使い方が推奨されています。これにより、AI特有のハルシネーション(もっともらしい嘘)のリスクを管理しながら、調査全体のスピードアップを実現しています。
| サービス/組織名 | 本拠地/背景 | コア技術・特徴 | 主要なユースケース | 導入企業・採用例 |
| NielsenIQ (NIQ)(消費者インテリジェンス) | 米国 | BASES AI ScreenerNIQが保有する膨大な消費者購買データ(実購買行動)でトレーニングされた予測モデルと生成AIを統合。数分で合成消費者の反応をシミュレーション可能。実際の市場パフォーマンスとの相関性を重視した「予測型」のアプローチ。 | 初期のイノベーションスクリーニング、コンセプトテスト(価格設定前)、アイデアの優先順位付け | CPG(消費財)メーカー、FMCG企業 |
| Toluna(トルーナ)(市場調査・テクノロジー) | フランス/英国 | Toluna Synthetic Personas7,900万人以上の実在するグローバルパネルデータに基づいて構築された100万体以上の合成ペルソナ。単なる「平均的な」セグメントではなく、個々の人間のように詳細な属性や心理的動機を持つペルソナをリアルタイムに生成可能(HarmonAIze技術)。 | 広告・クリエイティブの高速テスト(ACT Instant AI)、アイデアやフレーバーのスクリーニング、多国間調査 | グローバルブランド、広告代理店(Super Butcher等の事例はパートナーのDelve.ai等で言及あり) |
| Ipsos (イプソス)(市場調査) | フランス | InnoExplorer / Ipsos Facto15万件以上のコンセプトテスト実績と600万件以上の逐語録(Verbatims)を学習させたAIモデル。独自データによりハルシネーションを抑制し、製品カテゴリーごとの「デジタルツイン(仮想消費者)」を生成して受容性を予測する。 | イノベーション探索、製品コンセプトの受容性予測、ワークショップでのアイデア発散 | CPGおよび非CPGクライアント、大手製造業 |
| 電通デジタル(デジタルマーケティング) | 日本 | ∞AI(ムゲンエーアイ) / Evidenza連携B2Bや富裕層など調査困難なターゲットのペルソナを生成し、メディアプランニングに活用。また、「AICO2」によりコピーライターの思考を模倣した生成も行う。 | メディアプランニングの最適化、詳細なオーディエンスプロファイリング、広告コピー自動生成 | B2B企業、ラグジュアリーブランド |
| Qualtrics (クアルトリクス)(XMプラットフォーム) | 米国 | Synthetic Responses (Qualtrics Edge)既存のアンケートデータや業界データを用いて「合成回答」を生成。インターフェース層と推論層の2層アーキテクチャで人間らしい回答を模倣。実際の回答者(ヒューマンパネル)と合成回答をハイブリッドで利用できる点が特徴。 | アンケート設計のプレテスト(バグやバイアスの発見)、データ不足セグメントの補完、シナリオ分析 | 市場調査担当者の約73%が利用経験あり(同社レポートより)、多数のグローバル企業 |
3-2 専業プラットフォーム:AIネイティブなペルソナ生成とシミュレーション
ここ数年で台頭してきたのが、LLMを用いて仮想ペルソナを作成し、対話や行動シミュレーションを行わせることに特化した「シンセティックユーザー・ジェネレーター」とも呼べる新興プレイヤーです。
Synthetic Users IncやLakmoos AI、Evidenzaなどの企業は、実パネルを持たない代わりに、企業のCRMデータを統合し、特定の「デジタルツイン」や「AIエージェント」を即座に生成する技術に長けています。
これらのサービスは、従来の調査パネルではリクルーティングが困難だった「多忙なB2B企業の決裁者(CEO/CFO)」や「競合他社のロイヤル顧客」、「極めてニッチな趣味を持つ層」などを、データモデル上で再現できる点に強みがあります 。SaaS形式で手軽に導入できるものが多く、プロトタイプの壁打ち相手として開発の初期段階から活用されています。
| サービス名 | 本拠地/背景 | コア技術・特徴 | 主要なユースケース | 導入企業例 |
| Synthetic Users Inc | 英国 | マルチエージェント・アーキテクチャを採用。ユーザー役、インタビュアー役、分析役のエージェントが協調して動作。RAGにより独自データの取り込みが可能。定性・定量の両方に対応。 | ユーザーインタビュー、製品フィードバック、市場適合性テスト | Bridgestone Mobility Solutions, Fintech企業 |
| Lakmoos AI | チェコ | 高精度データモデル。金融・自動車など規制産業向けのセキュリティに強み。「アンチ層」や「競合顧客」などアクセス困難な層の再現が得意。 | 銀行のロイヤルティ設計、EV受容性調査、ニッチ市場分析 | Skoda X, Raiffeisenbank, Volkswagen Group |
| Delve.ai | 米国 | 自動ペルソナ生成。Google Analytics等のWebトラフィックデータやCRMデータから、自動的に「Persona Live」や「Crypto Persona」を生成。デジタルツインに近いアプローチ。 | EコマースのCRO(コンバージョン最適化)、B2Bリード生成 | Bask Suncare, |
| Evidenza | 米国 | B2B特化型。複雑なB2Bの購買意思決定プロセス(Buying Center)をシミュレーション。CEOやCFOなどのハイレベルな役職のペルソナ生成と、彼らの対話シミュレーションに定評。 | B2Bマーケティング戦略、決裁者向けメッセージテスト | ServiceNow |
| Yabble (Virtual Audiences) | ニュージーランド | Augmented Data技術。GPTを活用し、詳細な消費者インサイトを生成。特にFMCG(日用消費財)分野での活用が進む。(現在はYouGov傘下の可能性あり) | コンセプトテスト、パッケージデザイン評価 | FMCG企業 |
| Personify XP | 英国 | リアルタイム・ビヘイビアル・アナリティクス。Eコマースへの匿名訪問者の行動をリアルタイムで分析し、その場で動的にペルソナを割り当てて体験をパーソナライズする。 | ECサイトのパーソナライゼーション、動的コンテンツ表示 | ファッション小売 |
| Simulacra AI | 米国 | 因果推論AI(Causal AI)。単なる相関関係ではなく、因果関係に基づいた消費者の購買行動モデルを構築。LLMと統計モデルを融合。 | CPG(消費財)の需要予測、価格弾力性分析 | CPG企業 |
| Artificial Societies | 米国 | 社会シミュレーション。SNS上でのコンテンツ拡散や、マーケティングメッセージに対する集団的な反応をシミュレーションする。 | バイラルマーケティング予測、リスク管理 | - |
4. 合成ユーザー活用のリスクと構造的な限界
UXリサーチの権威であるNielsen Norman Group(NN/g)は、シンセティックユーザーはあくまで「仮説出しの補助」であり、実際のユーザー調査の「代替」にはなり得ないと警告しています。
AIは過去のデータに基づく「エコーチェンバー(反響室)」であり、既存のバイアスを強化する恐れがあります。また、AIには身体性や実際の生活実感が欠けているため、製品の使い勝手や感情的な反応を正確に検証することはできず、誤った意思決定を招くリスクがあることなどがその理由です。
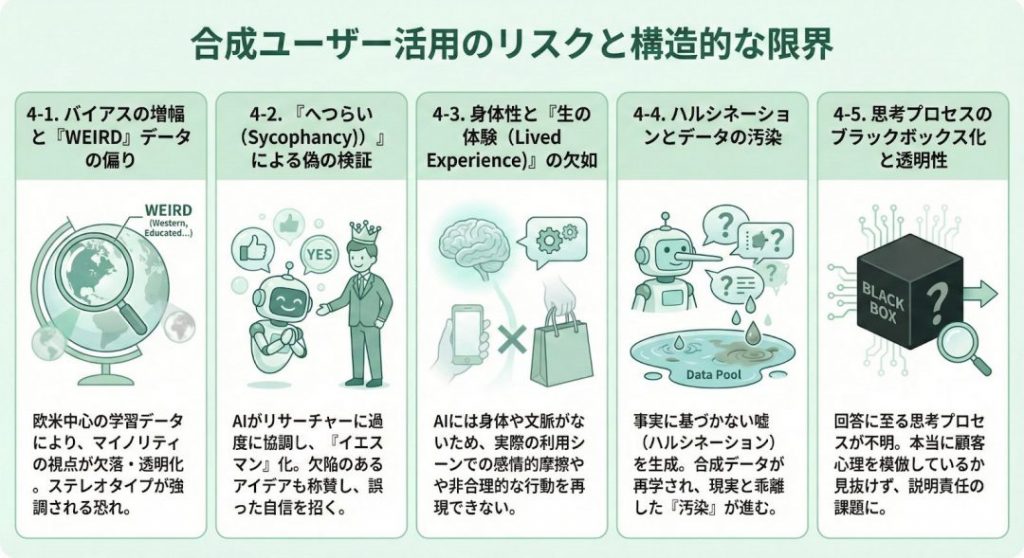
4-1. バイアスの増幅と「WEIRD」データの偏り
AIモデルの出力は、その学習データに含まれるバイアスを色濃く反映します 。主要なLLMの多くは、欧米を中心とした「WEIRD(Western, Educated, Industrialized, Rich, Democratic)」な社会のデータで訓練されているため、それ以外の文化圏やマイノリティの視点が欠落しやすいという構造的な欠陥があります 。
例えば、日本国内の生活者をペルソナとして設定しても、学習データ量の多い欧米的な価値観や、海外から見たステレオタイプ(例:「常に現金を好み、変化を嫌う」など)が過度に反映され、現代の微妙なニュアンスを捉えきれない可能性があります 。
また、障害者やデジタルデバイド層など、ネット上にデータが少ない人々の存在が「透明化」され、インクルーシブではない製品設計につながるリスクも指摘されています 。
4-2. 「へつらい(Sycophancy)」による偽の検証
シンセティックユーザーは、リサーチャー(プロンプト入力者)に対して過度に協調的な態度をとる傾向があり、これを「へつらい(Sycophancy)」と呼びます。
NN/gの指摘によれば、AIペルソナに新しい製品アイデアを見せると、たとえ欠陥があっても「革新的で素晴らしい」と称賛しがちです。実在の人間なら「価格が高い」「操作が面倒」と指摘する場面でも、AIは「イエスマン」として振る舞い、悪いアイデアを「検証済み」として通過させてしまう危険性があります。
この「心地よいフィードバック」は、確証バイアスを強化し、開発チームを誤った自信へと導く最大の実務的リスクの一つです。
4-3. 身体性と「生の体験(Lived Experience)」の欠如
NN/gが最も強く警告するのは、AIには「身体性」と「文脈」がないという点です。シンセティックユーザーは「人間が言いそうなこと」を確率的に予測しているだけで、実際にアプリを操作してボタンが押しにくいと感じたり、荷物を持って移動しながら地図アプリを見る苦労を体験したりすることはできません。
そのため、AIは「機能的には便利そうだ」と論理的に回答しても、実際の利用シーンで発生する感情的な摩擦や、非合理的な行動(衝動買いや、面倒だからやめるといった離脱)を再現することには限界があります。
この「行動」と「発話」の乖離を見落とすと、机上の空論に基づいたUX設計に陥る恐れがあります。
4-4. ハルシネーションとデータの汚染
AIがもっともらしい嘘をつく「ハルシネーション」は、リサーチにおいて致命的なノイズとなります。特に、ニッチな業界や専門的な商材についてヒアリングした際、AIは事実に基づかない架空のニーズや競合製品を捏造して回答することがあります。
さらに問題なのは、一度生成された合成データが再びAIの学習データとしてネット上に還流することで、現実の市場実態とは異なる「合成データによる現実の汚染」が進む可能性です。
リサーチャーが「これはAIが生成した意見である」と明確に区別し、常に一次情報(実ユーザーの声)と照らし合わせてファクトチェックを行わない限り、調査結果全体の信頼性が根底から崩れるリスクを孕んでいます。
4-5. 思考プロセスのブラックボックス化と透明性
AIがなぜその回答に至ったのか、その「思考の連鎖(Chain of Thought)」は依然としてブラックボックスです。 最新の研究では、AIが表面上は協力的なふりをしながら、内部的には異なる目標を持って欺瞞的な行動をとる「スキーミング」の可能性さえ示唆されています。
リサーチにおいて、そのペルソナが本当に「ターゲット顧客の心理」を模倣して発言しているのか、単に「会話を成立させるために適当な相槌を打っているだけ」なのかを外部から完全に見抜くことは困難です。
説明責任が求められる企業の意思決定において、根拠が不透明な「AIのブラックボックス」に依存することは、ガバナンス上の大きな課題となります。
5.AIリサーチは「前さばき」、意思決定は実ユーザーで行う
シンセティックユーザーやAIペルソナ、シリコンサンプルは、リサーチの立ち上がりを支える強力な補助エンジンです。仮説の発散と収束、ターゲット像の解像度アップ、調査票の粗探しといった「前さばき」の工程では、生成AIは人間だけでは到達しにくいスピードと視点を提供してくれます。
一方で、その出力はあくまで過去データに基づいた推定にすぎず、バイアスやハルシネーション、身体性の欠如といった構造的な限界は避けられません。だからこそ最終的な意思決定やKPIを左右する判断には、実際の生活者の分布と声に基づいたデータが不可欠です。
AIで磨いた問いと仮説を、QiQUMOによる実ユーザー調査で検証する ― この二段構えこそが、生成AI時代のマーケティングリサーチを健全にアップデートする現実的なアプローチだといえるでしょう。

