分散分析とは|簡単解説

分散分析のカンタン解説
分散分析は、平均値の仮説検定の方法であり、3つ以上のデータ群の平均を検定するために用います。各データ群の分散の比を見ることで、各データ群の平均値の差が有意なものであるかどうかを確率的に判定することを目的とします。分散分析はANOVA(Analysis of Variance)とも呼ばれます。
分散分析による仮説検定とは
仮説検定とは、データ群の検定統計量が一定の範囲(有意水準)にあるかどうかを基準として、仮説が正しいかどうかを判定することです。
分散分析は複数のデータ群の平均の仮説検定なので、「データ群の平均値に統計的な有意差はない」ことが帰無仮説であり、「データ群の平均値に統計的な有意差がある」ことが対立仮説となります。
ただし、どの群に差があるかは分散分析だけでは分かりません。
帰無仮説:帰無仮説とは、あることを証明するために、証明できないことを裏付けるための仮説であり、帰無仮説が否定(棄却)されれば、証明したいことが正しいと判定できます。帰無仮説に対して、証明したいことを対立仮説といいます。
分散分析で用いる検定統計量が有意水準(起こることがまれな確率)を上回れば、帰無仮説は棄却され、対立仮説である「データ群の平均値に有意な差がある」と判断できることになります。
分散分析の考え方
分散分析は、観測した複数のデータ群を比較する場合、平均の違いが統計的に意味のある差かどうかを判定します。
以下の、A、B、Cの母集団が異なる観測データが得られたとします。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 平均 | |
| A | 59 | 67 | 77 | 50 | 46 | 34 | 48 | 55 | 32 | 36 | 50.4 |
| B | 41 | 54 | 56 | 81 | 51 | 61 | 81 | 86 | 50 | 69 | 63.0 |
| C | 71 | 28 | 28 | 61 | 33 | 43 | 37 | 35 | 68 | 49 | 45.3 |
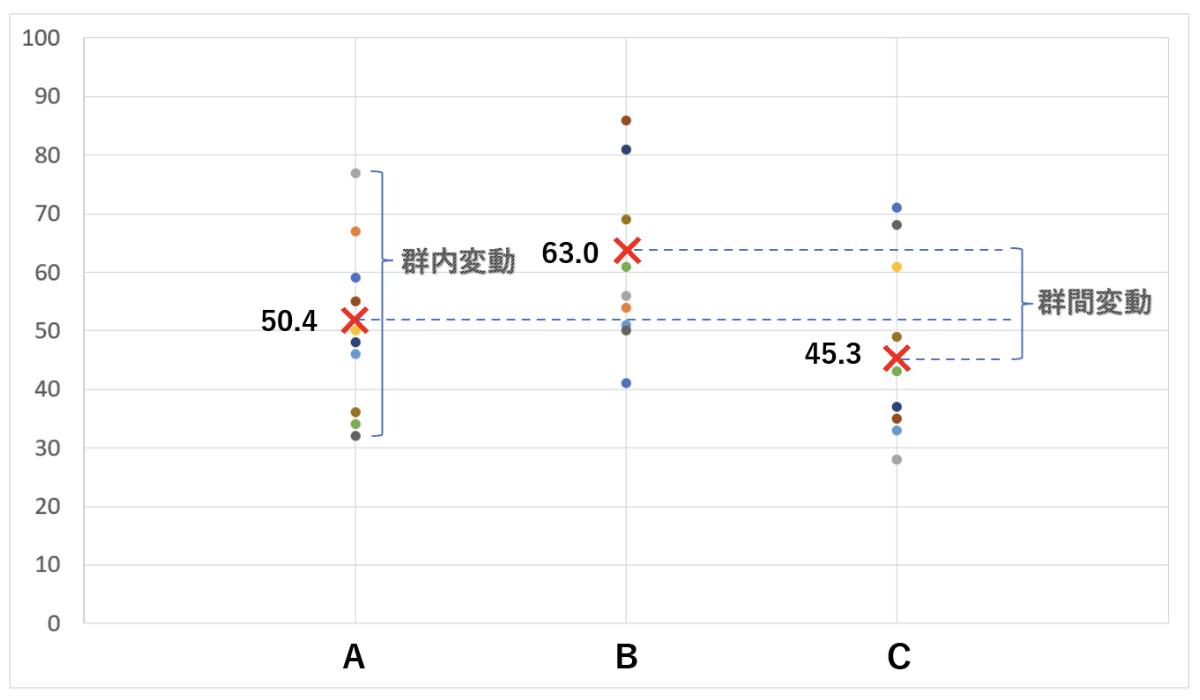
10個のデータからなるA、B、Cそれぞれのデータのバラつきが群内変動であり、A、B、Cの各平均値のバラつきを群間変動とみなすことができます。
実験や検査で分散分析が用いられる場合、データ群のことを水準、水準の違いを因子といいます。例えば、素材の厚みごとの強度を測定するケースでは「厚み」が因子にあたり、10mm、20mmなど具体的に設定した「厚さごとのグループ」が水準にあたります。
分散分析では群内変動と群間変動の分散の比を検定の判断基準に用い、判断基準となる検定統計量をF比といいます。
F比は以下の以下のイメージです。
F比 =群間変動(データ群間の平均のバラつき)群内変動(一つのデータ群のデータのバラつき) =群の違い誤差の大きさ
2つのデータ群についての平均値を比較する場合は t 検定を用います。3つ以上のデータ群がある場合でも2つずつの組み合わせで検定することが考えられますが、検定の多重性という問題が生じるため、3つ以上の比較では分散分析を用います。
分散分析の流れ
エクセルで分散分析を行う場合の流れをご紹介します。
エクセルの「データ分析」から「分散分析:一元配置」を選択し、上記のA、B、Cの観測データの分散分析表を出力すると以下の数値が得られます。
分散分析:一元配置
概要
| グループ | データの個数 | 合計 | 平均 | 分散 |
|---|---|---|---|---|
| A | 10 | 504 | 50.4 | 213.1555556 |
| B | 10 | 630 | 63 | 238.2222222 |
| C | 10 | 453 | 45.3 | 262.9 |
分散分析表
| 変動要因 | 変動 | 自由度 | 分散 | 観測された分散比 | P-値 | F境界値 |
|---|---|---|---|---|---|---|
| グループ間 | 1660.2 | 2 | 830.1 | 3.486458738 | 0.04499 | 3.354131 |
| グループ内 | 6428.5 | 27 | 238.0926 | ー | ー | ー |
| 合計 | 8088.7 | 29 | ー | ー | ー | ー |
分散分析表の各項目はF比を求めるための計算を示しています。
変動要因
グループ間、グループ内は、群間の変動か群内の変動かに対応しています。それぞれの分散を求めるということです。
変動
変動は分散を求める際の平方和のことです。グループ内の変動はA、B、Cそれぞれの群の平方和を合計したものです。グループ間の変動はA、B、Cそれぞれの(平均ー全体の平均)2 ✕10(データの個数)を算出し合計することで求められます。
自由度
自由度は分散を求める際のデータの個数のことです。標本平均を求めるためデータの個数ー1が自由度になります。グループ間は3つのグループで自由度が1ずつ消費されているため、データの個数をn-3として計算します。
分散
変動(平方和の合計)を自由度(データの個数)で割ることで分散が求められます。グループ間の変動1660.2を自由度2で割ると分散830.1が求められます。それと同様にグループ内の変動6428.5を自由度27で割ると、分散238.0926が求められます。
観測された分散比
一般的にはF値といわれます。前述したF比のことで、群間変動(グループ間の分散)である830.1を群内変動(グループ内の分散)238.0926で割った値となります。
P-値
P値は確率モデルの有意水準を指定する際の値であり、分散分析の場合はF分布の棄却域を見るための値です。一般的にはP-値が0.05以下であれば帰無仮説を棄却することができます。
F境界値
分散の比はF分布に従うことが知られており、観測された分散比であるF値がF境界値を上回れば、帰無仮説を棄却することができます。例の場合のF値は3.486459、F境界値が3.354131なのでF値が上回っており、A、B、Cの平均の差には統計的に有意な差がありそうだという結論になります。
繰り返しのある二元配置分散分析と繰り返しのない二元配置分散分析
ここまで述べた分散分析の方法は、因子が1つである一元配置分散分析の内容です。エクセルでは、分散分析には「一元配置」「繰り返しのある二元配置」「繰り返しのない二元配置」の3種類の選択肢があります。
因子が2つある場合の分散分析が二元配置分散分析の分散分析であり、「繰り返し」のあるなしは、水準にデータが複数存在するか1つだけかの違いです。
【繰り返しのある二元配置分散分析】
| 因子Y | |||||||||||
| 水準Y1 | 水準Y2 | ||||||||||
| 因子X | 水準X1 | 34 | 83 | 75 | 36 | 76 | 31 | 81 | 72 | 33 | 72 |
| 水準X2 | 84 | 70 | 43 | 41 | 77 | 80 | 64 | 38 | 34 | 73 | |
| 水準X3 | 67 | 71 | 43 | 62 | 54 | 66 | 66 | 42 | 57 | 49 | |
【繰り返しのない二元配置分散分析】
| 因子Y | ||||||
| 水準Y1 | 水準Y2 | 水準Y3 | 水準Y4 | 水準Y5 | ||
| 因子X | 水準X1 | 62 | 57 | 35 | 48 | 55 |
| 水準X2 | 84 | 80 | 74 | 68 | 66 | |
| 水準X3 | 67 | 66 | 53 | 72 | 69 | |
一元配置の分散分析では因子Xの違いに、有意な差がみられるかどうかの検定でしたが、二元配置の分散分析では新たに因子Yが加わります。
二元配置分散分析では因子Xと因子Yの平均を比較することで、どちらの因子の効果が大きいかを判断することができます。
また、繰り返しのある二元配置分散分析ではデータ全体のバラつきから因子Xと因子Yの不偏分散を取り除くことで、因子Xと因子Yの交互作用(相乗効果)を判定することができます。
まとめ
分散分析は実験計画法で用いられる仮説検定として一般的であるとともに、回帰分析系の一般線形モデルとしても用いられる応用範囲の広い分析手法です。正しく理解するためには統計の知識が求められ、他の検定手法との使い分けについても配慮する必要があります。
検定自体はエクセルをはじめとした統計ソフトを用いることで容易にできるため、さまざまなケースについて試してみることをおすすめします。